
2024
Urpi, N. A., Bagatella, M., Vlastelica, M., Martius, G.
Causal Action Influence Aware Counterfactual Data Augmentation
In Proceedings of the 41st International Conference on Machine Learning (ICML), 235, pages: 1709-1729, Proceedings of Machine Learning Research, (Editors: Salakhutdinov, Ruslan and Kolter, Zico and Heller, Katherine and Weller, Adrian and Oliver, Nuria and Scarlett, Jonathan and Berkenkamp, Felix), PMLR, July 2024 (inproceedings)
Geist, A. R., Frey, J., Zhobro, M., Levina, A., Martius, G.
Learning with 3D rotations, a hitchhiker’s guide to SO(3)
In Proceedings of the 41st International Conference on Machine Learning (ICML), 235, pages: 15331-15350, Proceedings of Machine Learning Research, (Editors: Salakhutdinov, Ruslan and Kolter, Zico and Heller, Katherine and Weller, Adrian and Oliver, Nuria and Scarlett, Jonathan and Berkenkamp, Felix), PMLR, July 2024 (inproceedings)
Paulus, A., Martius, G., Musil, V.
LPGD: A General Framework for Backpropagation through Embedded Optimization Layers
In Proceedings of the 41st International Conference on Machine Learning (ICML), 235, pages: 39989-40014, Proceedings of Machine Learning Research, (Editors: Salakhutdinov, Ruslan and Kolter, Zico and Heller, Katherine and Weller, Adrian and Oliver, Nuria and Scarlett, Jonathan and Berkenkamp, Felix), PMLR, July 2024 (inproceedings)
Ruaud, A., Sancaktar, C., Bagatella, M., Ratzke, C., Martius, G.
Modelling Microbial Communities with Graph Neural Networks
In Proceedings of the 41st International Conference on Machine Learning (ICML), 235, pages: 42742-42765, Proceedings of Machine Learning Research, (Editors: Salakhutdinov, Ruslan and Kolter, Zico and Heller, Katherine and Weller, Adrian and Oliver, Nuria and Scarlett, Jonathan and Berkenkamp, Felix), PMLR, July 2024 (inproceedings)
Spieler, A., Rahaman, N., Martius, G., Schölkopf, B., Levina, A.
The Expressive Leaky Memory Neuron: an Efficient and Expressive Phenomenological Neuron Model Can Solve Long-Horizon Tasks
In The Twelfth International Conference on Learning Representations (ICLR), May 2024 (inproceedings)
Khajehabdollahi, S., Zeraati, R., Giannakakis, E., Schäfer, T. J., Martius, G., Levina, A.
Emergent mechanisms for long timescales depend on training curriculum and affect performance in memory tasks
In The Twelfth International Conference on Learning Representations, ICLR 2024, May 2024 (inproceedings)
Gumbsch, C., Sajid, N., Martius, G., Butz, M. V.
Learning Hierarchical World Models with Adaptive Temporal Abstractions from Discrete Latent Dynamics
In The Twelfth International Conference on Learning Representations, ICLR 2024, May 2024 (inproceedings)
Yao, D., Xu, D., Lachapelle, S., Magliacane, S., Taslakian, P., Martius, G., von Kügelgen, J., Locatello, F.
Multi-View Causal Representation Learning with Partial Observability
The Twelfth International Conference on Learning Representations (ICLR), May 2024 (conference)
2023
Kolev, P., Martius, G., Muehlebach, M.
Online Learning under Adversarial Nonlinear Constraints
In Advances in Neural Information Processing Systems 36, December 2023 (inproceedings)
Sancaktar, C., Piater, J., Martius, G.
Regularity as Intrinsic Reward for Free Play
In Advances in Neural Information Processing Systems 37, December 2023 (inproceedings)
Zadaianchuk, A., Seitzer, M., Martius, G.
Object-Centric Learning for Real-World Videos by Predicting Temporal Feature Similarities
In Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS 2023), Advances in Neural Information Processing Systems 36, December 2023 (inproceedings)
Bagatella, M., Martius, G.
Goal-conditioned Offline Planning from Curious Exploration
In Advances in Neural Information Processing Systems 36, December 2023 (inproceedings)
Wang, Q., McCarthy, R., Bulens, D. C., McGuinness, K., O’Connor, N. E., Sanchez, F. R., Gürtler, N., Widmaier, F., Redmond, S. J.
Improving Behavioural Cloning with Positive Unlabeled Learning
7th Annual Conference on Robot Learning (CoRL), November 2023 (conference) Accepted
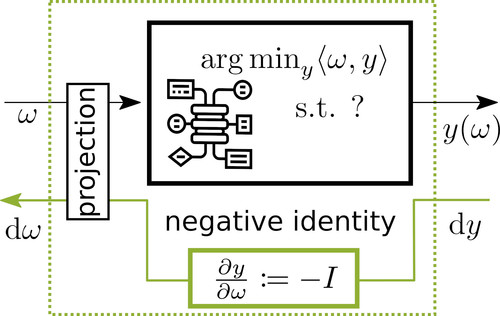
Sahoo, S., Paulus, A., Vlastelica, M., Musil, V., Kuleshov, V., Martius, G.
Backpropagation through Combinatorial Algorithms: Identity with Projection Works
In Proceedings of the Eleventh International Conference on Learning Representations, May 2023 (inproceedings) Accepted

Schumacher, P., Haeufle, D. F., Büchler, D., Schmitt, S., Martius, G.
DEP-RL: Embodied Exploration for Reinforcement Learning in Overactuated and Musculoskeletal Systems
In The Eleventh International Conference on Learning Representations (ICLR), May 2023 (inproceedings)

Gürtler, N., Blaes, S., Kolev, P., Widmaier, F., Wüthrich, M., Bauer, S., Schölkopf, B., Martius, G.
Benchmarking Offline Reinforcement Learning on Real-Robot Hardware
In Proceedings of the Eleventh International Conference on Learning Representations, The Eleventh International Conference on Learning Representations (ICLR), May 2023 (inproceedings)
Armengol Urpi, N., Bagatella, M., Hilliges, O., Martius, G., Coros, S.
Efficient Learning of High Level Plans from Play
In International Conference on Robotics and Automation, 2023 (inproceedings) Accepted

Eberhard, O., Hollenstein, J., Pinneri, C., Martius, G.
Pink Noise Is All You Need: Colored Noise Exploration in Deep Reinforcement Learning
In Proceedings of the Eleventh International Conference on Learning Representations (ICLR), The Eleventh International Conference on Learning Representations (ICLR), May 2023 (inproceedings)
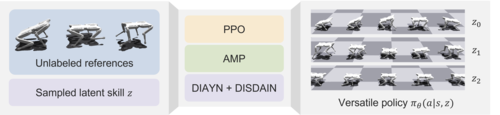
Li, C., Blaes, S., Kolev, P., Vlastelica, M., Frey, J., Martius, G.
Versatile Skill Control via Self-supervised Adversarial Imitation of Unlabeled Mixed Motions
In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), IEEE International Conference on Robotics and Automation (ICRA), May 2023 (inproceedings) Accepted
Seitzer, M., Horn, M., Zadaianchuk, A., Zietlow, D., Xiao, T., Simon-Gabriel, C., He, T., Zhang, Z., Schölkopf, B., Brox, T., Locatello, F.
Bridging the Gap to Real-World Object-Centric Learning
In Proceedings of the Eleventh International Conference on Learning Representations, The Eleventh International Conference on Learning Representations (ICLR), May 2023 (inproceedings)

2022
Li, C., Vlastelica, M., Blaes, S., Frey, J., Grimminger, F., Martius, G.
Learning Agile Skills via Adversarial Imitation of Rough Partial Demonstrations
Proceedings of the 6th Conference on Robot Learning (CoRL), Conference on Robot Learning (CoRL), December 2022 (conference) Accepted
Wochner, I., Schumacher, P., Martius, G., Büchler, D., Schmitt, S., Haeufle, D.
Learning with Muscles: Benefits for Data-Efficiency and Robustness in Anthropomorphic Tasks
Proceedings of the 6th Conference on Robot Learning (CoRL), 205, pages: 1178-1188, Proceedings of Machine Learning Research, (Editors: Liu, Karen and Kulic, Dana and Ichnowski, Jeff), PMLR, December 2022 (conference)
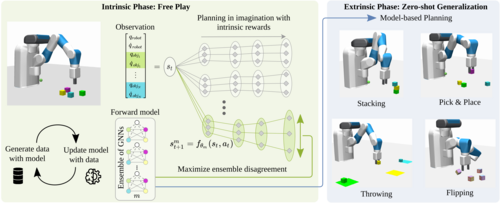
Sancaktar, C., Blaes, S., Martius, G.
Curious Exploration via Structured World Models Yields Zero-Shot Object Manipulation
In Advances in Neural Information Processing Systems 35 (NeurIPS 2022), pages: 24170-24183 , Curran Associates, Inc., 36th Annual Conference on Neural Information Processing Systems (NeurIPS 2022), December 2022 (inproceedings)
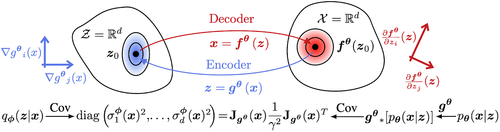
Reizinger*, P., Gresele*, L., Brady*, J., von Kügelgen, J., Zietlow, D., Schölkopf, B., Martius, G., Brendel, W., Besserve, M.
Embrace the Gap: VAEs Perform Independent Mechanism Analysis
Advances in Neural Information Processing Systems (NeurIPS 2022), 35, pages: 12040-12057, (Editors: S. Koyejo and S. Mohamed and A. Agarwal and D. Belgrave and K. Cho and A. Oh), Curran Associates, Inc., 36th Annual Conference on Neural Information Processing Systems, December 2022, *equal first authorship (conference)
Gürtler, N., Widmaier, F., Sancaktar, C., Blaes, S., Kolev, P., Bauer, S., Wüthrich, M., Wulfmeier, M., Riedmiller, M., Allshire, A., Wang, Q., McCarthy, R., Kim, H., Baek, J., Kwon, W., Qian, S., Toshimitsu, Y., Michelis, M. Y., Kazemipour, A., Raayatsanati, A., Zheng, H., Cangan, B. G., Schölkopf, B., Martius, G.
Real Robot Challenge 2022: Learning Dexterous Manipulation from Offline Data in the Real World
Proceedings of the NeurIPS 2022 Competitions Track, 220, pages: 133-150, Proceedings of Machine Learning Research, (Editors: Ciccone, Marco and Stolovitzky, Gustavo and Albrecht, Jacob), PMLR, December 2022 (conference)
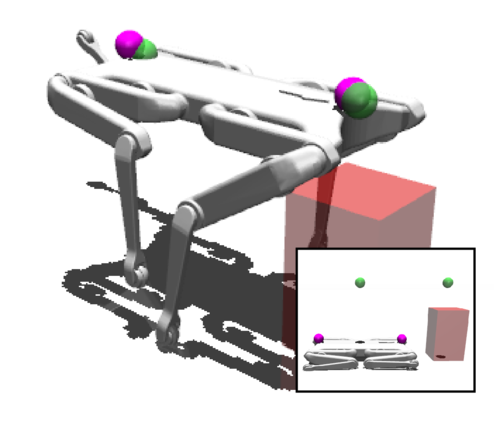
Vlastelica*, M., Blaes*, S., Pinneri, C., Martius, G.
Risk-Averse Zero-Order Trajectory Optimization
In Conference on Robot Learning, 164, PMLR, 5th Conference on Robot Learning (CoRL 2021) , 2022, *Equal Contribution (inproceedings)
Zadaianchuk, A., Martius, G., Yang, F.
Self-supervised Reinforcement Learning with Independently Controllable Subgoals
In Proceedings of the 5th Conference on Robot Learning (CoRL 2021) , 164, pages: 384-394, PMLR, 5th Conference on Robot Learning (CoRL 2021) , 2022 (inproceedings)
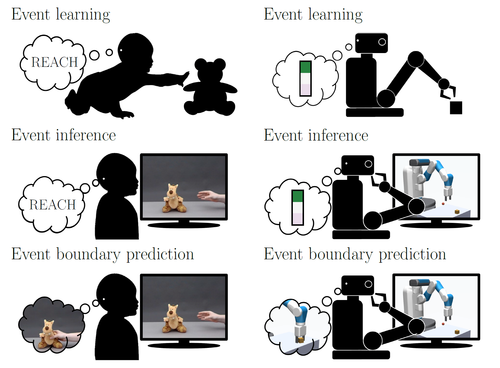
Gumbsch, C., Adam, M., Elsner, B., Martius, G., Butz, M. V.
Developing hierarchical anticipations via neural network-based event segmentation
In Proceedings of the IEEE International Conference on Development and Learning (ICDL 2022), pages: 1-8, 2022 IEEE International Conference on Development and Learning (ICDL), September 2022 (inproceedings)

Ghosh, P., Zietlow, D., Black, M. J., Davis, L. S., Hu, X.
InvGAN: Invertible GANs
In Pattern Recognition, pages: 3-19, Lecture Notes in Computer Science, 13485, (Editors: Andres, Björn and Bernard, Florian and Cremers, Daniel and Frintrop, Simone and Goldlücke, Bastian and Ihrke, Ivo), Springer, Cham, 44th DAGM German Conference on Pattern Recognition (DAGM GCPR 2022), September 2022 (inproceedings)
Zietlow, D., Lohaus, M., Balakrishnan, G., Kleindessner, M., Locatello, F., Schölkopf, B., Russell, C.
Leveling Down in Computer Vision: Pareto Inefficiencies in Fair Deep Classifiers
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages: 10410-10421, June 2022 (conference)
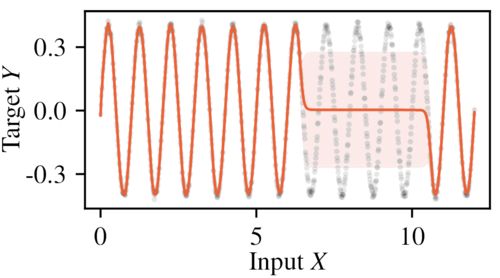
Seitzer, M., Tavakoli, A., Antic, D., Martius, G.
On the Pitfalls of Heteroscedastic Uncertainty Estimation with Probabilistic Neural Networks
International Conference on Learning Representations (ICLR 2022), Tenth International Conference on Learning Representations (ICLR 2022) , April 2022 (conference)
Fatemi, M., Tavakoli, A.
Orchestrated Value Mapping for Reinforcement Learning
International Conference on Learning Representations, April 2022 (conference)
Werner, M., Junginger, A., Hennig, P., Martius, G.
Uncertainty in Equation Learning
In GECCO ’22: Proceedings of the Genetic and Evolutionary Computation Conference Companion (GECCO), pages: 2298-2305, ACM, Genetic and Evolutionary Computation Conference (GECCO 2022) , 2022 (inproceedings)
2021
Gürtler, N., Büchler, D., Martius, G.
Hierarchical Reinforcement Learning with Timed Subgoals
In Advances in Neural Information Processing Systems 34, 26, pages: 21732-21743, (Editors: M. Ranzato and A. Beygelzimer and Y. Dauphin and P. S. Liang and J. Wortman Vaughan), Curran Associates, Inc., Red Hook, NY, 35th Conference on Neural Information Processing Systems (NeurIPS 2021), December 2021 (inproceedings)
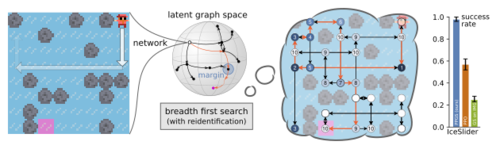
Bagatella, M., Olšák, M., Rolínek, M., Martius, G.
Planning from Pixels in Environments with Combinatorially Hard Search Spaces
In Advances in Neural Information Processing Systems 34, 30, pages: 24707-24718, Curran Associates, Inc., Red Hook, NY, 35th Conference on Neural Information Processing Systems (NeurIPS 2021), December 2021 (inproceedings)
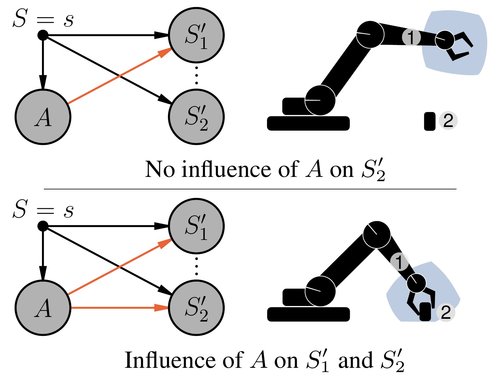
Seitzer, M., Schölkopf, B., Martius, G.
Causal Influence Detection for Improving Efficiency in Reinforcement Learning
In Advances in Neural Information Processing Systems 34 (NeurIPS 2021), 34, pages: 22905-22918, (Editors: M. Ranzato and A. Beygelzimer and Y. Dauphin and P. S. Liang and J. Wortman Vaughan), Curran Associates, Inc., Red Hook, NY, 35th Conference on Neural Information Processing Systems, December 2021 (inproceedings)
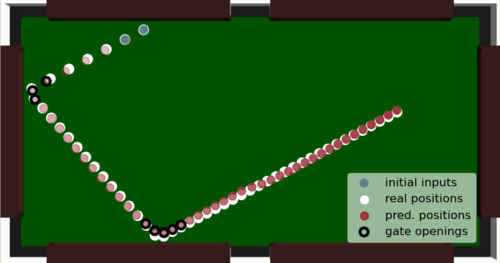
Gumbsch, C., Butz, M. V., Martius, G.
Sparsely Changing Latent States for Prediction and Planning in Partially Observable Domains
In Advances in Neural Information Processing Systems 34, 21, pages: 17518-17531, (Editors: M. Ranzato and A. Beygelzimer and Y. Dauphin and P. S. Liang and J. Wortman Vaughan), Curran Associates, Inc., Red Hook, NY, 35th Conference on Neural Information Processing Systems (NeurIPS 2021), December 2021 (inproceedings)
Hornakova, A. K. T. S. P. R. M. R. B. H. R.
Making Higher Order MOT Scalable: An Efficient Approximate Solver for Lifted Disjoint Paths
Proceedings 2021 IEEE/CVF INTERNATIONAL CONFERENCE ON COMPUTER VISION (ICCV 2021), pages: 6310-6320, IEEE, ICCV 2021, October 2021 (conference)
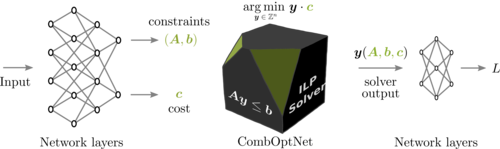
Paulus, A., Rolínek, M., Musil, V., Amos, B., Martius, G.
CombOptNet: Fit the Right NP-Hard Problem by Learning Integer Programming Constraints
In Proceedings of the 38th International Conference on Machine Learning, 139, pages: 8443-8453, Proceedings of Machine Learning Research, (Editors: Meila, Marina and Zhang, Tong), PMLR, The Thirty-eighth International Conference on Machine Learning (ICML), July 2021 (inproceedings)
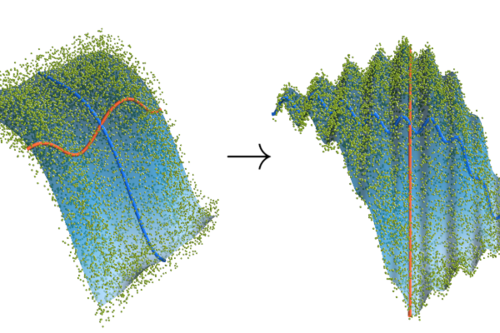
Zietlow, D., Rolinek, M., Martius, G.
Demystifying Inductive Biases for (Beta-)VAE Based Architectures
In Proceedings of the 2021 International Conference on Machine Learning (ICML), 139, pages: 12945-12954, Proceedings of Machine Learning Research , The 38th International Conference on Machine Learning (ICML 2021), July 2021 (inproceedings)
Vlastelica, M., Rolinek, M., Martius, G.
Neuro-algorithmic Policies Enable Fast Combinatorial Generalization
In Proceedings of the 2021 International Conference on Machine Learning (ICML), The Thirty-eighth International Conference on Machine Learning (ICML), July 2021 (inproceedings)
Prosi, J., Khajehabdollahi, S., Giannakakis, E., Martius, G., Levina, A.
The dynamical regime and its importance for evolvability, task performance and generalization
In The 2021 Conference on Artificial Life, MIT Press, July 2021 (inproceedings)
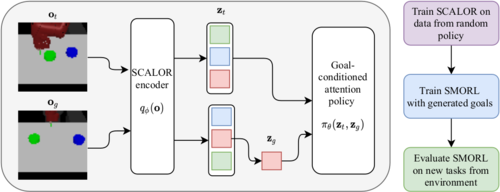
Zadaianchuk*, A., Seitzer*, M., Martius, G.
Self-supervised Visual Reinforcement Learning with Object-centric Representations
In 9th International Conference on Learning Representations (ICLR 2021), May 2021, *equal contribution (inproceedings)
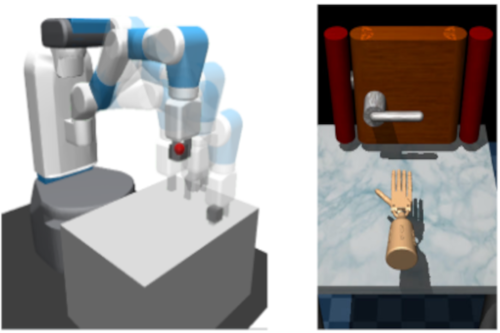
Pinneri*, C., Sawant*, S., Blaes, S., Martius, G.
Extracting Strong Policies for Robotics Tasks from Zero-order Trajectory Optimizers
In The Ninth International Conference on Learning Representations (ICLR), 9th International Conference on Learning Representations (ICLR 2021) , May 2021, *equal contribution (inproceedings)
2020
Rolínek, M., Swoboda, P., Zietlow, D., Paulus, A., Musil, V., Martius, G.
Deep Graph Matching via Blackbox Differentiation of Combinatorial Solvers
In Computer Vision – ECCV 2020, 28, pages: 407-424, Lecture Notes in Computer Science, 12373, (Editors: Vedaldi, Andrea and Bischof, Horst and Brox, Thomas and Frahm, Jan-Michael), Springer, Cham, 16th European Conference on Computer Vision (ECCV 2020) , August 2020 (inproceedings)
Zhu, J., Martius, G.
Fast Non-Parametric Learning to Accelerate Mixed-Integer Programming for Hybrid Model Predictive Control
IFAC-PapersOnLine, 21rst IFAC World Congress, 53(2):5239-5245, Elsevier, Amsterdam, 21rst IFAC World Congress, July 2020 (conference)
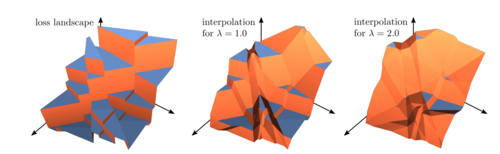
Rolínek, M., Musil, V., Paulus, A., Vlastelica, M., Michaelis, C., Martius, G.
Optimizing Rank-based Metrics with Blackbox Differentiation
In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2020), pages: 7617 - 7627, IEEE, Piscataway, NJ, IEEE/CVF International Conference on Computer Vision and Pattern Recognition (CVPR 2020), June 2020, Best paper nomination (inproceedings)
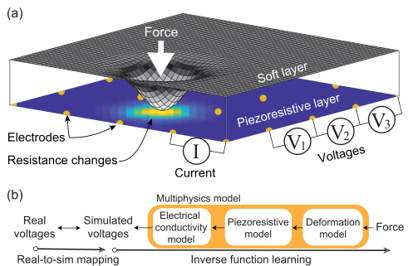
Lee, H., Park, H., Serhat, G., Sun, H., Kuchenbecker, K. J.
Calibrating a Soft ERT-Based Tactile Sensor with a Multiphysics Model and Sim-to-real Transfer Learning
In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), pages: 1632-1638, IEEE International Conference on Robotics and Automation (ICRA 2020), May 2020 (inproceedings)

Vlastelica*, M., Paulus*, A., Musil, V., Martius, G., Rolínek, M.
Differentiation of Blackbox Combinatorial Solvers
In International Conference on Learning Representations, ICLR’20, May 2020, *Equal Contribution (inproceedings)
Agudelo-España, D., Zadaianchuk, A., Wenk, P., Garg, A., Akpo, J., Grimminger, F., Viereck, J., Naveau, M., Righetti, L., Martius, G., Krause, A., Schölkopf, B., Bauer, S., Wüthrich, M.
A Real-Robot Dataset for Assessing Transferability of Learned Dynamics Models
IEEE International Conference on Robotics and Automation (ICRA), pages: 8151-8157, IEEE, 2020 (conference)