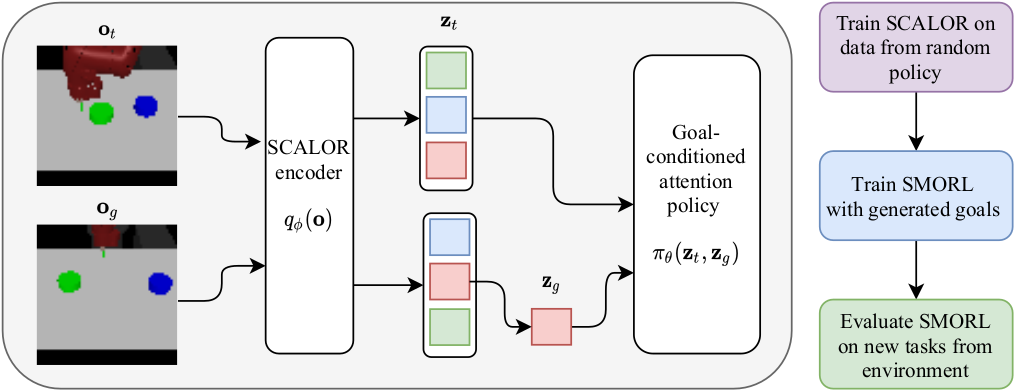
Autonomous agents need large repertoires of skills to act reasonably on new tasks that they have not seen before. To learn such skills an agent can first learn a structured representation of the environment and then use it for the construction of the goal space. In particular, we propose to use object-centric representations learned from images without supervision.
In the first project [ ], we showed that object-centric representations could be learned from image observations collected by the random agent. Such representations serves as subgoals and could be used to solve challenging rearranging and pushing tasks in the environment without any external goals.
In the second project [ ], we investigate the problem of composing object-centric subgoals to solve complex compositional tasks, such as rearranging up to 6 different objects. To tackle this problem, we first infer the object interaction graph from object dynamics data and then use it for the construction of the independently controllable subgoals. Such subgoals could be combined in a sequence of compatible subgoals and allow the agent to solve each subgoal without destroying previously solved subgoals.