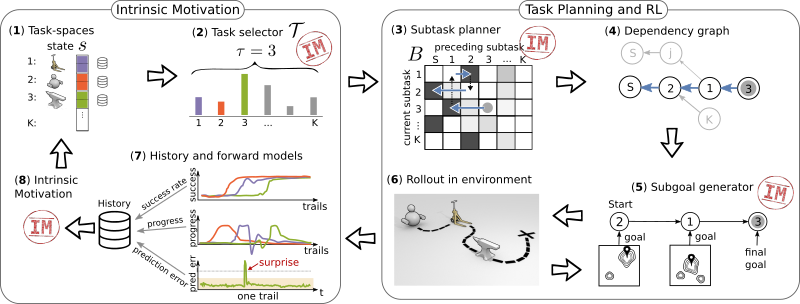
Overview of CWYC method. All components except (1) are learned. The left part shows how intrinsic motivation is used to distribute learning resources between tasks the agent can make progress in. The right part depicts the planning pipeline used for actually executing a task in the environment.
True autonomy in the real world is not bound to a single task under fixed environmental dynamics. In fact, tasks are hardly ever clearly specified, e.g. through well-shaped rewards, and it really is left to the agent to determine what tasks to pursue in order to prepare for unknown future challenges.
In [ ], we equip a Reinforcement Learning (RL) agent with different abilities that support this self-organized learning process and make it efficient. The goal is to have an agent that explores its environment and thereby figures out how to solve a number of tasks that require it to manipulate different parts of the state space. Once the agent learns all tasks sufficiently well, we can ask the agent to solve a certain task by manipulating the corresponding part of the state space until a goal state is achieved. In the end, the agent should be capable of controlling all controllable parts of its state.
The main abilities we equip the agent with are depicted in the figure and are described as follows: A task selector (part [2] in the figure) that allows the agent to distribute its available resource budget among all possible tasks it could learn (part [1]) such that, at any given time, most of the resource budget is spent on tasks that the agent can make the most progress in. A task planner (part [3]) that learns a potentially existing inter-dependency between tasks, i.e. if one task can be solved faster or is only enabled by another task. A dependency graph (part [4]) that the agent uses to plan subtask sequences that allow it to solve a final desired task. A subgoal generator (part [5]) that generates for each subtask in the plan a goal state that, if reached by the agent, makes it easier to solve the next subtask. All components are learned concurrently from an intrinsic motivation signal (part [8]) that is computed from the experience the agent collects while autonomously interacting with the environment (parts [6, 7] in the figure).
In this work, we pair an explicit (or fixed) but general planning structure with data-driven learning to solve challenging control tasks. By extracting information about the interrelationship between tasks from the data, the agent's planner can specialize on the specific set of problems it faces in the current environment. One next step in this line of research is to make the planning structure itself more flexible so that it can be fully learned or dynamically adapted to better fit the specific needs of the problems at hand.
Confronted with the open-ended learning setting, we select learning progress as the main driving force of exploration and as an additional training signal for differentiating between task-relevant and task-irrelevant information in the training data.
Another future direction of research is to find other types of intrinsic motivation that can drive the exploration behavior of the agent.
The code, the poster presented at NeurIPS 2019 and a 3 min summary video can be found here.